Posted on 25 Jan 2019
The last month of ExVenture saw a continuation of refactors and some exciting changes in Gossip & Grapevine.
Links for MidMUD & ExVenture:
Gossip
Gossip got a few nice improvements. I added the ability to scrape telnet based games that aren’t hooked up to the chat network. There is a protocol called MUD Server Stats Protocol (MSSP) that probes telnet connections for game information. Gossip now sweeps every hour for compatible games, adding to the list of online games.
Achievements are also on the move. You can add achievements to your game and have them display. I haven’t been working on unlocking them yet, but the core is there. I was delayed on unlocking them because of the weird split in Grapevine and Gossip.
Grapevine
Speaking of that, Gossip and Grapevine have merged into just Grapevine. I added all of the features to Gossip, and then renamed Gossip to Grapevine. This split was sort of awkward and made it confusing for people signing up. It was also harder than it needed to be to sync new stuff from Gossip to Grapevine. With this in place it should be much easier to add new features.
Continuing with that, I’ve been working on the design for Grapevine. There’s a new home page that displays online games with their new cover art. This makes it look more familiar to other gaming stores, even if Grapevine isn’t a store.
Proficiencies
I’ve also been working on some new game features. I’ve been working on proficiencies which is a way of gating things behind a rank. An example might be a Swimming proficiency, which you can require 5 ranks in in order to move between two rooms. If you have 4 ranks or under, you are prevented from moving through. Players can hone ranks by spending experience points.
I think this is a nice simple mechanic that can be used in interesting ways. No proficiencies are bundled into ExVenture, you only have the ones you design for your game. You can watch me work on honing proficiencies on this YouTube video.
CI & Test refactors
I worked on setting up CI again for ExVenture (and Grapevine.) As part of this I worked a lot on refactoring the test suite to remove global state Agents. Instead I started sending messages to the test process as code interacts with remote processes. It was pretty nice to get this working and also dramatically stabalized the test runs.
Also as part of CI, I’m building a new release inside of Docker and pushing to S3. I don’t have a nice URL for these yet, but the top commit on the master branch should have a built release you can use to deploy. I want to figure out how to generate a clean URL for easy use. I would like to do a blog about how this works come next month.
Small Tweaks
- Player URL is case insenitive on grapevine
- Display channels that a game is connected to on gossip
- ExVenture (un)subscribes to Gossip channel updates
- Lots of new metrics
- Refactor Game.Help
- Continuing migrating formatting calls to the new template system
- Wrap calls to injected modules (as module attributes) in a single module
- Help updates across the cluster
- Password resets for Gossip accounts
- Work continues on the react web client
Social Updates
I’ll be at Lonestar Elixir at the end of next month talking about getting metrics from your application with Prometheus. I hope to see you there!
I’ve been streaming over on Twitch every Monday at 12 PM EST doing ExVenture or Grapevine development. Join me over at https://www.twitch.tv/smartlogictv.
Next Month
Next Month I would like to continue expanding what proficiencies can influence. I think it would be cool to get them in front of items and a few other things. I will also keep pushing forward on the new Grapevine. I’m looking at adding a fairly simple web client to Grapevine to easily connect to telnet games, among other things.
Posted on 28 Dec 2018
The last month of ExVenture saw a lot of internal refactors and deployment updates.
Links for MidMUD & ExVenture:
NPC Events
Events got a huge refactor to consolidate a lot of duplicate code around actions. Previously it was not straight forward which events could have what actions, and each event implemented the action separately. This refactor sets up events and actions as full structs and modules.
Now each event lists what actions it allows. Each action is implemented once. All events also can have multiple actions in order to have more realistic NPCs.
Check out the documentation for these events.
Pull Request.
Web Client in React
Lorecrafting in the discord has started on a major refactor of the web client, switching over to react. It’s still fairly in progress, but is moving along nicely.
Venture Markup Language
In order to help the web client and more solidify the internal markup format, the Venture Markup Language (VML) was named. Nothing much changes other than giving it a name and actually doing parsing instead of regex replace.
There is now a set of leex and yecc parsing modules. VML now has some documentation.
Pull Request
Deployment
ExVenture isn’t the easiest thing to deploy in production at the moment, so I finally got around to working on making that easier. As part of this I finally got around to writing ansible scripts and a small deployment script to help everything out.
See more on deploying ExVenture in the last post.
ExVenture World
Continuing with this, I have started a new hosting service called ExVenture World. This uses the ansible scripts and terraform to create new game instances in Digital Ocean very quickly. I plan on leaving this not fully automated for a while and eventually automate it fully if more people are interested in hosted games.
If you are interested in a hosted version, please let me know over on the discord channel.
Small Tweaks
- Distillery 2.0 config provider, for everything
- Gossip design tweaks
- Use systemd
- Migrate to new servers
- Builder role
- Grapevine only login
Social Updates
A few times people have requested a forum to be set up for ExVenture, this now exists over at forums.exventure.org.
We have a few new patrons on the Patron, thanks for supporting!
I will be at Lonestar Elixir 2019 showing off adding prometheus metrics to your application, and Gossip will be my demo app. If you’re there, make sure to say hello!
Next Month
For the next month, I’m working on some new game mechanics, the first of which is proficiencies. I am hoping to get back around to some of the other mechanics that are already in and expand them a bit, such as items. I would like to start moving on achievements for Gossip as well.
Posted on 14 Dec 2018
Up until recently, how to deploy ExVenture has been a bit of a mystery. I have done it a few times, for MidMUD most notably, but it was fairly tricky to do and entirely done by hand.
I also relied on some parts of linux like /etc/profile.d/ to ensure environment variables were loaded, so starting the application could only be done by a login shell. It wasn’t the best, but hey, it worked.
This week however, a few more people were starting to get interested in ExVenture and asking about how to host it and I finally got embarassed enough to get something more formal around how to deploy it.
I also started a hosting service called ExVenture World if anyone is interested in having a game without having to deploy it. See the announcement post for ExVenture World on Patreon.
Vagrant
Vagrant is a tool for spinning up local VMs quickly, and being able to quickly recreate them from a base box. We’re going to use this to get a local install going. Install Vagrant before continuing.
After a few minutes, you’ll have a local machine you can ssh into. Vagrant will provision python for us on first boot so that we can run ansible on it in our next step.
Something I’ve tended to have issues with on Vagrant is SSH known host issues on recreating a VM. I just learned about this snippet you can place in ~/.ssh/config to ignore host checks. Do make sure it’s only enabled for 127.0.0.1 as this is very insecure.
Host 127.0.0.1
HostName 127.0.0.1
UserKnownHostsFile /dev/null
StrictHostKeyChecking no
IdentitiesOnly yes
Ansible
Ansible is a tool for configuring remote servers. They run playbooks to make sure a server is configured the same each time. See more information about it and how to install it on their site.
First install the roles you’ll be using to provision the server. This uses Ansible Galaxy to pull down remote roles.
ansible-galaxy install -r deploy/requirements.yml
Next, run the setup playbook on the local machine. This will configure the local VM to be provisioned for the next few steps. Make sure to update this line in the deploy/group_vars/all.yml line to include your GitHub user. It will download any keys you have associated to your account and let you into the deploy user.
ansible-playbook -l local deploy/setup.yml
There are now two files on the machine that need to be edited, /etc/exventure.config.exs and /etc/nginx/sites-enabled/exventure. The nginx config file just needs to know what it’s domain name is. The exventure.config.exs file needs more modification. Any empty string "" should be filled in with the required information.
You should set up SMTP so your game can send emails, this will also require setting the from address.
The endpoint and networking lines both need to know the new domain name for your game as well. You should also connect your game to Gossip. It’s more fun that way.
Certbot
Once you are configured, restart nginx and then configure SSL via certbot.
sudo systemctl restart nginx
sudo certbot --nginx
Follow the prompts for configuring your new domain. You should set the game to redirect any HTTP traffic to the HTTPS port.
Deploying
Next you can deploy your game, the first deploy you should seed as well. ExVenture comes with a simple deploy script that will handle most of this for you. The last argument should be the fully qualified domain name that you previously set up. It will try SSH’ing in as deploy.
Before deploying, make sure to generate a production release with the release.sh script. Note that this needs to be run on a linux system. You cannot deploy an erlang release built on a mac to a linux remote.
./release.sh
./deploy.sh --seed my-game.example.com
On future deploys, you only need to use
./deploy.sh my-game.example.com
A Remote Server
The previous steps got a local VM ready. Getting a remote machine is not that much harder. I recommend using Digital Ocean as your VPS of choice, ExVenture World is hosted there.
Once you create a droplet (using Ubuntu 18.04), SSH in and install python.
Next setup a new host file named deploy/host_remote with the following:
[remote]
the.ip.or.domain
ansible-playbook -i deploy/host_remote deploy/setup.yml
And the rest is the same. Configure the game, configure certbot, generate a release, and deploy it.
Conclusion
Hopefully this helps you get a remote ExVenture game set up and running. If you have any questions please come by the Discord group.
Posted on 28 Nov 2018
The last month of ExVenture has been pretty good. ExVenture was on an Elixir podcast and did an introduction meetup with UtahElixir. There were also a lot of Gossip related updates.
Links for MidMUD & ExVenture:
Podcasts
I was on the Elixir Mix podcast, episode 27. On it, I talked about all of the different projects that ExVenture encompasses. I also went into some of the topics I covered in the Going Multi-Node ElixirConf talk I gave. Definitely give it a listen!
I also talked with UtahElixir about ExVenture and introduced it to the group. Mark Ericksen is an organizer for UtahElixir and wants to use ExVenture as a way of teaching various elixir topics and wants to go over various parts of it over the next few meetups. How cool!
Multiple Characters
I finally wrapped up the split apart from a single user account, to a user account that has characters. This was a fairly long process as it touched a lot of pieces of the code. I have been slowly going through everything so as to not feel like it was a suffocating refactor and the work finally paid off.
I was very happy with how easy this final refactor ended up being after the positioning ExVenture for this with previous refactors.
You can see this in Pull Request #90.
Grapvine Login
I have been talking with the MUD Coders Guild for a what’s next thing for Grapevine and we came up with the idea of Grapvine being an OAuth provider. I have previously written one so I figured it’d be fun to do again. With multiple characters in place, now was the time to add it into ExVenture as well.
I couldn’t use existing OAuth code because they ship with their own backing tables, and I wanted to reuse the games table. If you update ExVenture and are connected to Gossip, you now support Grapevine authentication. It takes some small extra configuration on Gossip’s end to get redirect URIs in place, but otherwise that’s it.
You can see this in Pull Request #91 and Pull Request #4.
Gossip
Gossip has gotten some work as well. I rewrote the underlying sync code to push around versioned payloads. This lets me capture deletes in addition to creates and updates.
With this in place, I was able to add in in-game events. You can add events to your game and they will be displayed on Grapevine. I would like to get a nice calendar view for this, but I went with simple until some data starts getting added in.
Gossip and Grapevine also got some minor styling tweaks. The homepages for each should better explain what they are.
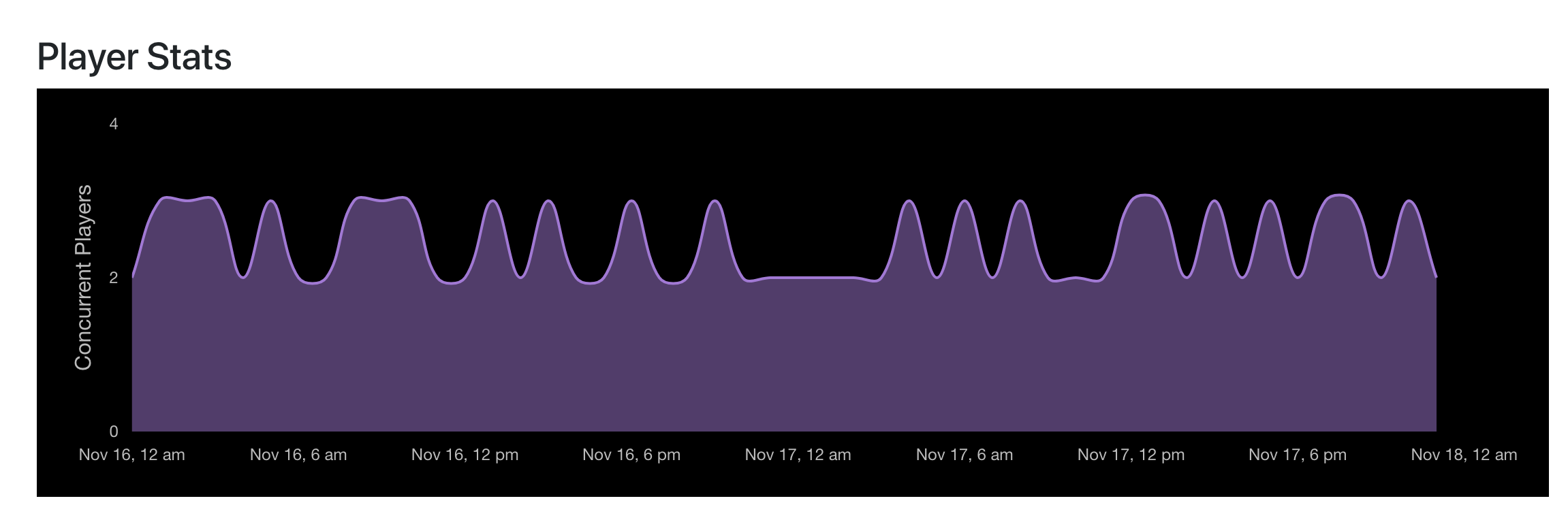
Gossip also tracks player count over time now and generates nice looking charts. This is viewable in Grapevine.
Gossip Refactors
The Gossip server and clients both got major refactors to their socket code. I was able to do a cool event router of sorts for the server. This can be seen here.
The elixir client for Gossip was also updated and recieved a 1.0 version. I blogged about this recently, check it out.
Small Tweaks
- Grapevine - display game connection status
- Refactor
Game.Format into smaller sub modules
- Fix the overworld map editor to allow for adding exits
- Gossip - delay sending game offline messages
- Grapevine - password resets
- Update raisin deps
- Gossip client - telemetry events
- Gossip - migrate to telemetry
- Gossip - require players to be online to send tells
- Social emotes now actually broadcast to the room you’re in
Social Updates
This month was pretty good for ExVenture on the social front. Lots of new stars across all of the projects!
I went to The Big Elixir earlier this month and gave my Going Multi-Node talk again. I met a lot of new people who were previously into MUDs or thought they seemed cool and are new to MUDs. Welcome everyone I met from The Big Elixir.
There are several new patrons over at the Patreon as well. Welcome and thanks for supporting the project!
The discord group has several new members in the last month.
Next Month
I am planning on refactoring the event system behind NPCs next. I am currently scoping out what I would like it to look like so this should happen. It will be a big undertaking but I think well worth the effort.
I am still looking at achievements as well. Progress is slow but it is happening. I am still trying to figure out some sync issues with them but they should be do-able. With the new sync in place for Gossip -> Grapevine these should be pretty easy to get going as well.
Posted on 15 Nov 2018
I recently did a pretty big refactor for the Gossip Elixir client. I’d like to show off what I did for that. For a brief background, Gossip sends events over the websocket connection. A sample event might be:
{
"event": "channels/broadcast",
"ref": "89036074-446f-41ab-b87a-44ef1f962f2e",
"payload": {
"channel": "gossip",
"message": "Hello everyone!",
"game": "ExVenture",
"name": "Player"
}
}
You can see all of the events over at the Gossip Docs.
Client Flow
The client connects to Gossip via the Gossip.Socket server. This is a Websockex process, which is a little different than your standard GenServer. It might eventually be swapped out to be a Gun client.
The flow of data goes as such:
New websocket frame
Full code
defmodule Gossip.Socket do
# ...
def handle_frame({:text, message}, state) do
case Events.receive(state, message) do
{:ok, state} ->
{:ok, state}
{:reply, message, state} ->
{:reply, {:text, Poison.encode!(message)}, state}
# other return values
end
end
# ...
end
When the client gets a new websocket frame, the socket process calls down to a lower level module.
Handling the event
Full code
defmodule Gossip.Socket.Events do
# ...
def receive(state, message) do
with {:ok, message} <- Poison.decode(message),
{:ok, state} <- process(state, message) do
{:ok, state}
else
{:reply, message, state} ->
{:reply, message, state}
end
end
# ...
end
The frame is decoded to an event and then processed.
Pattern matching on the event
Full code
defmodule Gossip.Socket.Events do
# ...
def process(state, message = %{"event" => "channels/" <> _}) do
Core.handle_receive(state, message)
end
def process(state, message = %{"event" => "players/" <> _}) do
Players.handle_receive(state, message)
end
# ...
end
Each event has a general scheme of noun/verb, such as channels/broadcast. This pattern matches on the just the noun part and pushes it lower into the module for processing.
Pattern matched on the specific event
Full code
Full code
defmodule Gossip.Socket.Core do
# ...
def handle_receive(state, message = %{"event" => "channels/broadcast"}) do
process_channel_broadcast(state, message)
end
def process_channel_broadcast(state, %{"payload" => payload}) do
message = %Message{
channel: payload["channel"],
game: payload["game"],
name: payload["name"],
message: payload["message"],
}
core_module(state).message_broadcast(message)
{:ok, state}
end
# ...
end
Here the event is fully pattern matched and calls to the internal function. I like to do it this way to keep it similar to GenServers and keeping the handle_* functions skinny.
Testing
With the client broken up into fairly small pieces, it helps encourage testing and keeps it simple to test.
Prior to this refactor, the Gossip client had almost no tests. This is due to each event module being broken up into separate elixir modules and having separate processing functions for each event.
See testing in action.
Conclusion
I hope you poke around the rest of the client. I also recommend taking a look around the server side of Gossip since that got a big refactor as well. One really cool section is the “event router” macro I set up to generate the server side receive functions.
